Home
Welcome to the SCALPEL-Extraction wiki! This wiki has the aim to explain everything surrounding the second part of the SCALPEL3 Library.
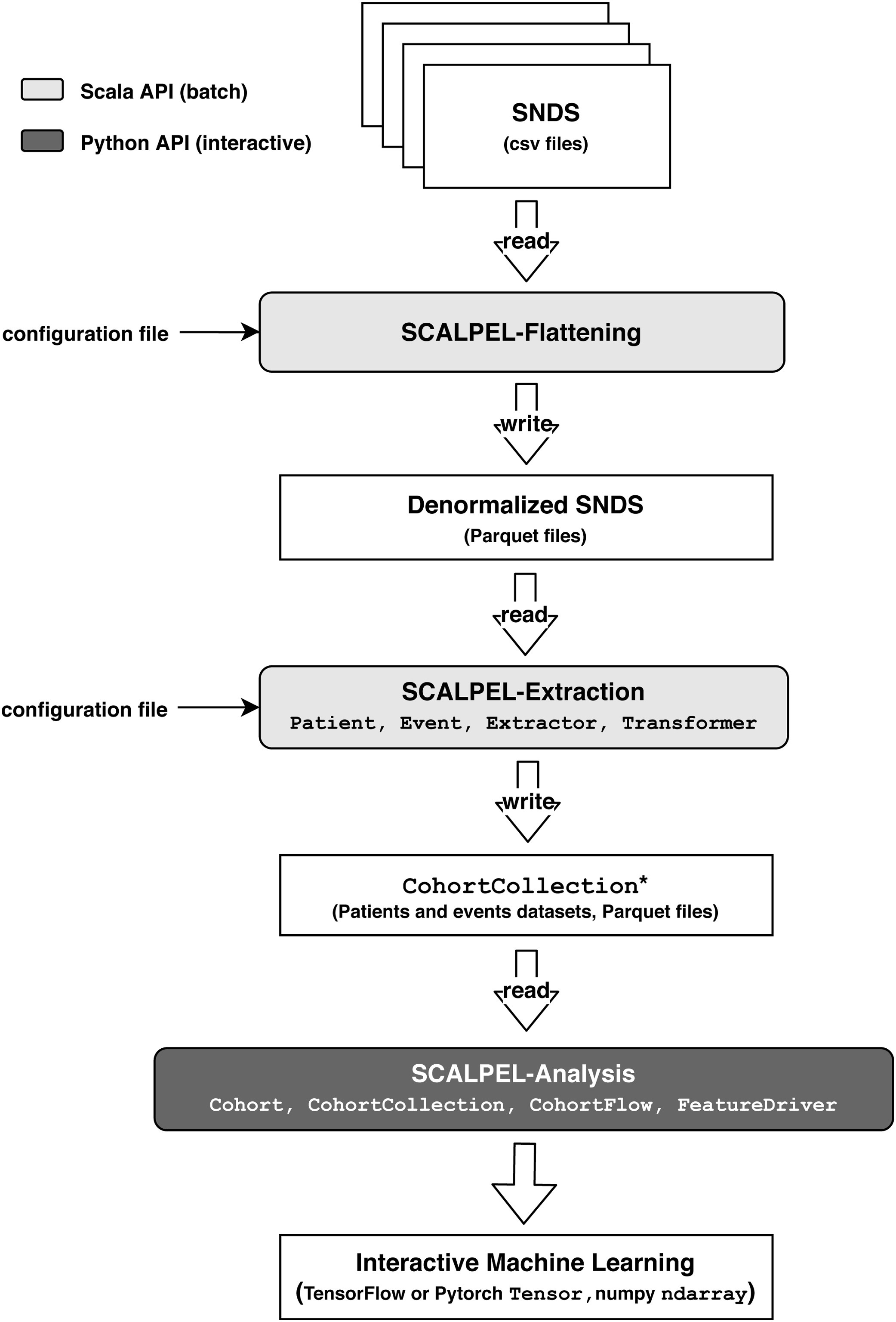
As SCALPEL-Flattening and SCALPEL-Extraction perform batch operations, they need to read (resp. write) input (resp. output) data from the file-system (local or HDFS). They are implemented in Scala in order to access Spark's low-level API and take advantage of functional programming and static typing, resulting in rigorous automated testing (94% of the Scala code is covered by unit tests). Both can be configured through textual configuration files or be used as libraries. SCALPEL-Analysis is a python module implemented in Python/PySpark and designed for interactive use. It can be used in a Jupyter notebook for instance. This workflow is illustrated in following Fig.